基本概念
在深入解读Lucene之前,先了解下Lucene的几个基本概念,以及这几个概念背后隐藏的一些东西。
Index(索引)
类似数据库的表的概念,但是与传统表的概念会有很大的不同。传统关系型数据库或者NoSQL数据库的表,在创建时至少要定义表的Scheme,定义表的主键或列等,会有一些明确定义的约束。
而Lucene的Index,则完全没有约束。
Lucene的Index可以理解为一个文档收纳箱,你可以往内部塞入新的文档,或者从里面拿出文档,但如果你要修改里面的某个文档,则必须先拿出来修改后再塞回去。
这个收纳箱可以塞入各种类型的文档,文档里的内容可以任意定义,Lucene都能对其进行索引。
Document(文档)
类似数据库内的行或者文档数据库内的文档的概念,一个Index内会包含多个Document。
写入Index的Document会被分配一个唯一的ID,即Sequence Number(更多被叫做DocId),关于Sequence Number后面会再细说。
Field(字段)
一个Document会由一个或多个Field组成,Field是Lucene中数据索引的最小定义单位。
Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等,Lucene根据Field的类型(FieldType)来判断该数据要采用哪种类型的索引方式(Invert Index、Store Field、DocValues或N-dimensional等),关于Field和FieldType后面会再细说。
Term和Term Dictionary
Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。
Term Dictionary即Term词典,是根据条件查找Term的基本索引。
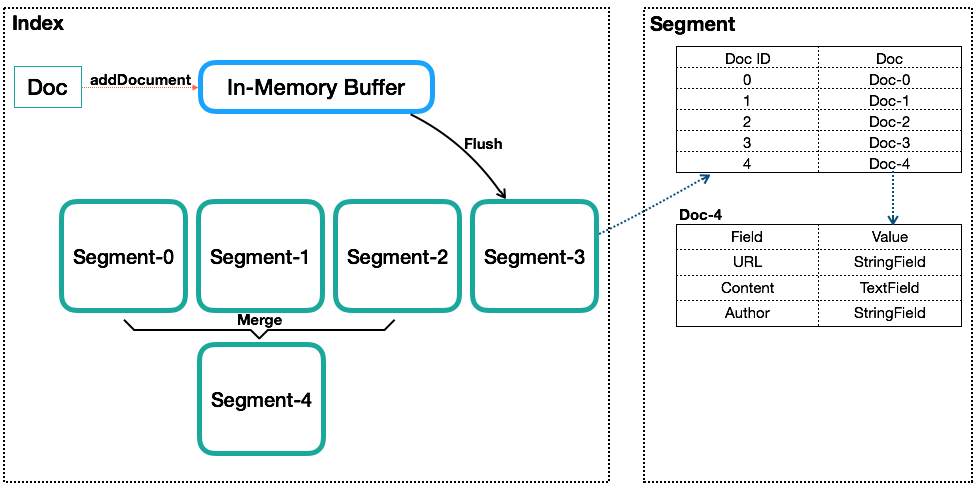
Segment
一个Index会由一个或多个sub-index构成,sub-index被称为Segment。
Lucene的Segment设计思想,与LSM类似但又有些不同,继承了LSM中数据写入的优点,但是在查询上只能提供近实时而非实时查询。
Lucene中的数据写入会先写内存的一个Buffer(类似LSM的MemTable,但是不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是Batch和Append,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并,这点与LSM对SSTable的Merge类似。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这也就是为什么Lucene被称为提供近实时而非实时查询的原因。读了它的代码后,发现它并不是不能实现数据写入即可查,只是实现起来比较复杂。原因是Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非实时构建,目的是为了构建最高效索引。当然它可引入另外一套索引机制,在数据实时写入时即构建,但这套索引实现会与当前Segment内索引不同,需要引入额外的写入时索引以及另外一套查询机制,有一定复杂度。
Sequence Number
Sequence Number(后面统一叫DocId)是Lucene中一个很重要的概念,数据库内通过主键来唯一标识一行,而Lucene的Index通过DocId来唯一标识一个Doc。
不过有几点要特别注意:
-
DocId实际上并不在Index内唯一,而是Segment内唯一,Lucene这么做主要是为了做写入和压缩优化。那既然在Segment内才唯一,又是怎么做到在Index级别来唯一标识一个Doc呢?方案很简单,Segment之间是有顺序的,举个简单的例子,一个Index内有两个Segment,每个Segment内分别有100个Doc,在Segment内DocId都是0-100,转换到Index级的DocId,需要将第二个Segment的DocId范围转换为100-200。
-
DocId在Segment内唯一,取值从0开始递增。但不代表DocId取值一定是连续的,如果有Doc被删除,那可能会存在空洞。
-
一个文档对应的DocId可能会发生变化,主要是发生在Segment合并时。
Lucene内最核心的倒排索引,本质上就是Term到所有包含该Term的文档的DocId列表的映射。所以Lucene内部在搜索的时候会是一个两阶段的查询,第一阶段是通过给定的Term的条件找到所有Doc的DocId列表,第二阶段是根据DocId查找Doc。Lucene提供基于Term的搜索功能,也提供基于DocId的查询功能。
DocId采用一个从0开始底层的Int32值,是一个比较大的优化,同时体现在数据压缩和查询效率上。
例如数据压缩上的Delta策略、ZigZag编码,以及倒排列表上采用的SkipList等,这些优化后续会详述。
索引类型
Lucene中支持丰富的字段类型,每种字段类型确定了支持的数据类型以及索引方式,目前支持的字段类型包括LongPoint、TextField、StringField、NumericDocValuesField等。
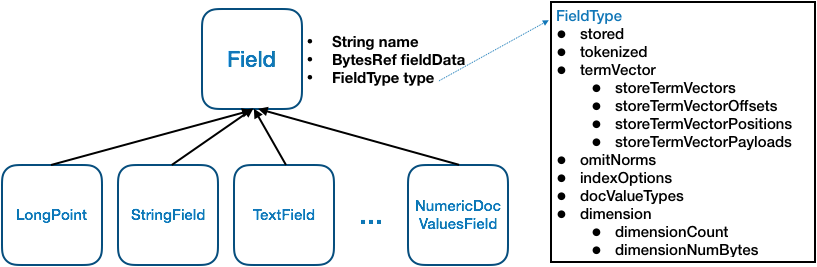
如图是Lucene中对于不同类型Field定义的一个基本关系,所有字段类都会继承自Field这个类,Field包含3个重要属性:name(String)、fieldsData(BytesRef)和type(FieldType)。name即字段的名称,fieldsData即字段值,所有类型的字段的值最终都会转换为二进制字节流来表示。type是字段类型,确定了该字段被索引的方式。
FieldType是一个很重要的类,包含多个重要属性,这些属性的值决定了该字段被索引的方式。
Lucene提供的多种不同类型的Field,本质区别就两个:
一是不同类型值到fieldData定义了不同的转换方式;二是定义了FieldType内不同属性不同取值的组合。
这种模式下,你也能够通过自定义数据以及组合FieldType内索引参数来达到定制类型的目的。
要理解Lucene能够提供哪些索引方式,只需要理解FieldType内每个属性的具体含义,我们来一个一个看:
属性含义
stored: 代表是否需要保存该字段,如果为false,则lucene不会保存这个字段的值,而搜索结果中返回的文档只会包含保存了的字段。
tokenized: 代表是否做分词,在lucene中只有TextField这一个字段需要做分词。
termVector: 这篇文章很好的解释了term vector的概念,简单来说,term vector保存了一个文档内所有的term的相关信息,包括Term值、出现次数(frequencies)以及位置(positions)等,是一个per-document inverted index,提供了根据docid来查找该文档内所有term信息的能力。对于长度较小的字段不建议开启term verctor,因为只需要重新做一遍分词即可拿到term信息,而针对长度较长或者分词代价较大的字段,则建议开启term vector。Term vector的用途主要有两个,一是关键词高亮,二是做文档间的相似度匹配(more-like-this)。
omitNorms: Norms是normalization的缩写,lucene允许每个文档的每个字段都存储一个normalization factor,是和搜索时的相关性计算有关的一个系数。Norms的存储只占一个字节,但是每个文档的每个字段都会独立存储一份,且Norms数据会全部加载到内存。所以若开启了Norms,会消耗额外的存储空间和内存。但若关闭了Norms,则无法做index-time boosting(elasticsearch官方建议使用query-time boosting来替代)以及length normalization。
indexOptions: Lucene提供倒排索引的5种可选参数(NONE、DOCS、DOCS_AND_FREQS、DOCS_AND_FREQS_AND_POSITIONS、DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS),用于选择该字段是否需要被索引,以及索引哪些内容。
docValuesType: DocValue是Lucene 4.0引入的一个正向索引(docid到field的一个列存),大大优化了sorting、faceting或aggregation的效率。DocValues是一个强schema的存储结构,开启DocValues的字段必须拥有严格一致的类型,目前Lucene只提供NUMERIC、BINARY、SORTED、SORTED_NUMERIC和SORTED_SET五种类型。
dimension:Lucene支持多维数据的索引,采取特殊的索引来优化对多维数据的查询,这类数据最典型的应用场景是地理位置索引,一般经纬度数据会采取这个索引方式。
StringField
来看下 Lucene 中对 StringField 的一个定义:
/** A field that is indexed but not tokenized: the entire
* String value is indexed as a single token. For example
* this might be used for a 'country' field or an 'id'
* field. If you also need to sort on this field, separately
* add a {@link SortedDocValuesField} to your document. */
public final class StringField extends Field {
/** Indexed, not tokenized, omits norms, indexes
* DOCS_ONLY, not stored. */
public static final FieldType TYPE_NOT_STORED = new FieldType();
/** Indexed, not tokenized, omits norms, indexes
* DOCS_ONLY, stored */
public static final FieldType TYPE_STORED = new FieldType();
static {
TYPE_NOT_STORED.setOmitNorms(true);
TYPE_NOT_STORED.setIndexOptions(IndexOptions.DOCS);
TYPE_NOT_STORED.setTokenized(false);
TYPE_NOT_STORED.freeze();
TYPE_STORED.setOmitNorms(true);
TYPE_STORED.setIndexOptions(IndexOptions.DOCS);
TYPE_STORED.setStored(true);
TYPE_STORED.setTokenized(false);
TYPE_STORED.freeze();
}
}
StringFiled有两种类型索引定义,TYPE_NOT_STORED和TYPE_STORED,唯一的区别是这个Field是否需要Store。
从其他的几个属性也可以解读出,StringFiled选择omitNorms,需要进行倒排索引并且不需要被分词。
