前言
可能很多 Java 程序员对 TCP 的理解只有一个三次握手,四次握手的认识,我觉得这样的原因主要在于 TCP 协议本身稍微有点抽象(相比较于应用层的 HTTP 协议);其次,非框架开发者不太需要接触到 TCP 的一些细节。其实我个人对 TCP 的很多细节也并没有完全理解,这篇文章主要针对微信交流群里有人提出的长连接,心跳问题,做一个统一的整理。
在 Java 中,使用 TCP 通信,大概率会涉及到 Socket、Netty,本文将借用它们的一些 API 和设置参数来辅助介绍。
长连接与短连接
TCP 本身并没有长短连接的区别 ,长短与否,完全取决于我们怎么用它。
- 短连接:每次通信时,创建 Socket;一次通信结束,调用 socket.close()。这就是一般意义上的短连接,短连接的好处是管理起来比较简单,存在的连接都是可用的连接,不需要额外的控制手段。
- 长连接:每次通信完毕后,不会关闭连接,这样可以做到连接的复用。 长连接的好处是省去了创建连接的耗时。
短连接和长连接的优势,分别是对方的劣势。想要图简单,不追求高性能,使用短连接合适,这样我们就不需要操心连接状态的管理;想要追求性能,使用长连接,我们就需要担心各种问题:比如 端对端连接的维护,连接的保活 。
长连接还常常被用来做数据的推送,我们大多数时候对通信的认知还是 request/response 模型,但 TCP 双工通信的性质决定了它还可以被用来做双向通信。在长连接之下,可以很方便的实现 push 模型,长连接的这一特性在本文并不会进行探讨,有兴趣的同学可以专门去搜索相关的文章。
短连接没有太多东西可以讲,所以下文我们将目光聚焦在长连接的一些问题上。纯讲理论未免有些过于单调,所以下文我借助一些 RPC 框架的实践来展开 TCP 的相关讨论。
服务治理框架中的长连接
前面已经提到过,追求性能时,必然会选择使用长连接,所以借助 Dubbo 可以很好的来理解 TCP。我们开启两个 Dubbo 应用,一个 server 负责监听本地 20880 端口(众所周知,这是 Dubbo 协议默认的端口),一个 client 负责循环发送请求。执行 lsof -i:20880 命令可以查看端口的相关使用情况:

*:20880 (LISTEN)说明了 Dubbo 正在监听本地的 20880 端口,处理发送到本地 20880 端口的请求- 后两条信息说明请求的发送情况,验证了 TCP 是一个双向的通信过程,由于我是在同一个机器开启了两个 Dubbo 应用,所以你能够看到是本地的 53078 端口与 20880 端口在通信。我们并没有手动设置 53078 这个客户端端口,它是随机的。通过这两条信息,阐释了一个事实: 即使是发送请求的一方,也需要占用一个端口 。
- 稍微说一下 FD 这个参数,他代表了 文件句柄 ,每新增一条连接都会占用新的文件句柄,如果你在使用 TCP 通信的过程中出现了
open too many files的异常,那就应该检查一下,你是不是创建了太多连接,而没有关闭。细心的读者也会联想到长连接的另一个好处,那就是会占用较少的文件句柄。
长连接的维护
因为客户端请求的服务可能分布在多个服务器上,客户端自然需要跟对端创建多条长连接,我们遇到的第一个问题就是如何维护长连接。
1 | // 客户端 |
在 Dubbo 中,客户端和服务端都使用 ip:port 维护了端对端的长连接,Channel 便是对连接的抽象。我们主要关注 NettyHandler 中的长连接,服务端同时维护一个长连接的集合是 Dubbo 的额外设计,我们将在后面提到。
这里插一句,解释下为什么我认为客户端的连接集合要重要一点。TCP 是一个双向通信的协议,任一方都可以是发送者,接受者,那为什么还抽象了 Client 和 Server 呢?因为 建立连接这件事就跟谈念爱一样,必须要有主动的一方,你主动我们就会有故事 。Client 可以理解为主动建立连接的一方,实际上两端的地位可以理解为是对等的。
连接的保活
这个话题就有的聊了,会牵扯到比较多的知识点。首先需要明确一点,为什么需要连接的保活?当双方已经建立了连接,但因为网络问题,链路不通,这样长连接就不能使用了。需要明确的一点是,通过 netstat,lsof 等指令查看到连接的状态处于 ESTABLISHED 状态并不是一件非常靠谱的事,因为连接可能已死,但没有被系统感知到,更不用提假死这种疑难杂症了。如果保证长连接可用是一件技术活。
连接的保活:KeepAlive
首先想到的是 TCP 中的 KeepAlive 机制。KeepAlive 并不是 TCP 协议的一部分,但是大多数操作系统都实现了这个机制(所以需要在操作系统层面设置 KeepAlive 的相关参数)。KeepAlive 机制开启后,在一定时间内(一般时间为 7200s,参数 tcp_keepalive_time)在链路上没有数据传送的情况下,TCP 层将发送相应的 KeepAlive 探针以确定连接可用性,探测失败后重试 10(参数 tcp_keepalive_probes)次,每次间隔时间 75s(参数 tcp_keepalive_intvl),所有探测失败后,才认为当前连接已经不可用。
在 Netty 中开启 KeepAlive:
1 | bootstrap.option(ChannelOption.SO_KEEPALIVE, true) |
Linux 操作系统中设置 KeepAlive 相关参数,修改 /etc/sysctl.conf 文件:
1 | net.ipv4.tcp_keepalive_time=90 |
KeepAlive 机制是在网络层面保证了连接的可用性 ,但站在应用框架层面我们认为这还不够。主要体现在三个方面:
- KeepAlive 的开关是在应用层开启的,但是具体参数(如重试测试,重试间隔时间)的设置却是操作系统级别的,位于操作系统的
/etc/sysctl.conf配置中,这对于应用来说不够灵活。 - KeepAlive 的保活机制只在链路空闲的情况下才会起到作用,假如此时有数据发送,且物理链路已经不通,操作系统这边的链路状态还是
ESTABLISHED,这时会发生什么?自然会走 TCP 重传机制,要知道默认的 TCP 超时重传,指数退避算法也是一个相当长的过程。 - KeepAlive 本身是面向网络的,并不面向于应用,当连接不可用,可能是由于应用本身的 GC 频繁,系统 load 高等情况,但网络仍然是通的,此时,应用已经失去了活性,连接应该被认为是不可用的。
我们已经为应用层面的连接保活做了足够的铺垫,下面就来一起看看,怎么在应用层做连接保活。
连接的保活:应用层心跳
终于点题了,文题中提到的 心跳 便是一个本文想要重点强调的另一个重要的知识点。上一节我们已经解释过了,网络层面的 KeepAlive 不足以支撑应用级别的连接可用性,本节就来聊聊应用层的心跳机制是实现连接保活的。
如何理解应用层的心跳?简单来说,就是客户端会开启一个定时任务,定时对已经建立连接的对端应用发送请求(这里的请求是特殊的心跳请求),服务端则需要特殊处理该请求,返回响应。如果心跳持续多次没有收到响应,客户端会认为连接不可用,主动断开连接。不同的服务治理框架对心跳,建连,断连,拉黑的机制有不同的策略,但大多数的服务治理框架都会在应用层做心跳,Dubbo/HSF 也不例外。
应用层心跳的设计细节
以 Dubbo 为例,支持应用层的心跳,客户端和服务端都会开启一个 HeartBeatTask,客户端在 HeaderExchangeClient 中开启,服务端将在 HeaderExchangeServer 开启。文章开头埋了一个坑:Dubbo 为什么在服务端同时维护 Map<String,Channel> 呢?主要就是为了给心跳做贡献,心跳定时任务在发现连接不可用时,会根据当前是客户端还是服务端走不同的分支,客户端发现不可用,是重连;服务端发现不可用,是直接 close。
1 | // HeartBeatTask |
Dubbo 2.7.x 相比 2.6.x 做了定时心跳的优化,使用
HashedWheelTimer更加精准的控制了只在连接闲置时发送心跳。
再看看 HSF 的实现,并没有设置应用层的心跳,准确的说,是在 HSF2.2 之后,使用 Netty 提供的 IdleStateHandler 更加优雅的实现了应用的心跳。
1 | ch.pipeline() |
处理 userEventTriggered 中的 IdleStateEvent 事件
1 |
|
对于客户端,HSF 使用 SendHeartbeat 来进行心跳,每次失败累加心跳失败的耗时,当超过最大限制时断开乱接;对于服务端 HSF 使用 CloseIdle 来处理闲置连接,直接关闭连接。一般来说,服务端的闲置时间会设置的稍长。
熟悉其他 RPC 框架的同学会发现,不同框架的心跳机制真的是差距非常大。心跳设计还跟连接创建,重连机制,黑名单连接相关,还需要具体框架具体分析。
除了定时任务的设计,还需要在协议层面支持心跳。最简单的例子可以参考 nginx 的健康检查,而针对 Dubbo 协议,自然也需要做心跳的支持,如果将心跳请求识别为正常流量,会造成服务端的压力问题,干扰限流等诸多问题。
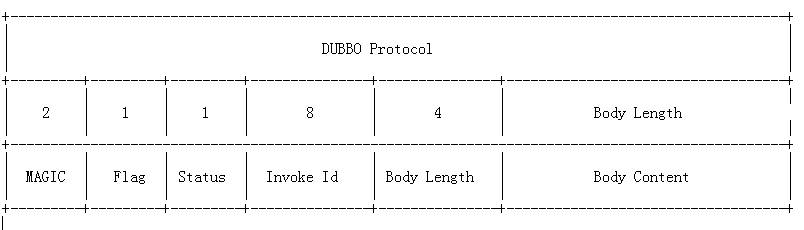
其中 Flag 代表了 Dubbo 协议的标志位,一共 8 个地址位。低四位用来表示消息体数据用的序列化工具的类型(默认 hessian),高四位中,第一位为 1 表示是 request 请求,第二位为 1 表示双向传输(即有返回 response), 第三位为 1 表示是心跳事件 。
心跳请求应当和普通请求区别对待。
注意和 HTTP 的 KeepAlive 区别对待
- HTTP 协议的 KeepAlive 意图在于连接复用,同一个连接上串行方式传递请求 - 响应数据
- TCP 的 KeepAlive 机制意图在于保活、心跳,检测连接错误。
这压根是两个概念。
KeepAlive 常见错误
启用 TCP KeepAlive 的应用程序,一般可以捕获到下面几种类型错误
ETIMEOUT 超时错误,在发送一个探测保护包经过 (tcp_keepalive_time + tcp_keepalive_intvl * tcp_keepalive_probes) 时间后仍然没有接收到 ACK 确认情况下触发的异常,套接字被关闭
1
java.io.IOException: Connection timed out
EHOSTUNREACH host unreachable(主机不可达) 错误,这个应该是 ICMP 汇报给上层应用的。
1
java.io.IOException: No route to host
链接被重置,终端可能崩溃死机重启之后,接收到来自服务器的报文,然物是人非,前朝往事,只能报以无奈重置宣告之。
1
java.io.IOException: Connection reset by peer
总结
有三种使用 KeepAlive 的实践方案:
- 默认情况下使用 KeepAlive 周期为 2 个小时,如不选择更改,属于误用范畴,造成资源浪费:内核会为每一个连接都打开一个保活计时器,N 个连接会打开 N 个保活计时器。 优势很明显:
- TCP 协议层面保活探测机制,系统内核完全替上层应用自动给做好了
- 内核层面计时器相比上层应用,更为高效
- 上层应用只需要处理数据收发、连接异常通知即可
- 数据包将更为紧凑
- 关闭 TCP 的 KeepAlive,完全使用应用层心跳保活机制。由应用掌管心跳,更灵活可控,比如可以在应用级别设置心跳周期,适配私有协议。
- 业务心跳 + TCP KeepAlive 一起使用,互相作为补充,但 TCP 保活探测周期和应用的心跳周期要协调,以互补方可,不能够差距过大,否则将达不到设想的效果。
各个框架的设计都有所不同,例如 Dubbo 使用的是方案三,但阿里内部的 HSF 框架则没有设置 TCP 的 KeepAlive,仅仅由应用心跳保活。和心跳策略一样,这和框架整体的设计相关。
欢迎关注我的微信公众号:「Kirito 的技术分享」

