导读
腾讯云 Elasticsearch Service(ES)是基于开源搜索引擎 Elasticsearch 打造的高可用、可伸缩的云端全托管的 Elasticsearch 服务,包含 Kibana 及常用插件,并集成了安全、SQL、机器学习、告警、监控等高级特性(X-Pack)。本文描述在实际使用中,经常会遇到的ES集群负载不均的问题,并结合多种场景进行分析、解决,以及如何避免。
作者简介
岳涛
腾云忆想大数据产品架构师,多年分布式、高并发大数据系统的研发、系统架构设计经验,擅长主流大数据架构技术平台的落地和实施。目前专注于大数据架构相关组件的研究推广和最佳实践的沉淀,致力于帮助企业完成数字化转型。
一、背景
ES集群在某些情况下会出现CPU使用率高的现象,具体有两种表现:
1. 个别节点CPU使用率远高于其他节点;
2. 集群中所有节点CPU使用率都很高。
本篇文章我们着重讲解第一种情况。
二、问题现象

集群在某些情况下会个别节点CPU使用率远高于其他节点的现象,从监控中可以明显看到某些节点CPU使用率居高不下。
三、原因
出现这种情况,由于表面上看集群读写都不高,导致很难快速从监控上找到根因。所以需要细心观察,从细节中找答案,下面我们介绍几种可能出现的场景以及排查思路。
原因一:Shard设置不合理
1. 登录Kibana控制台,在开发工具中执行以下命令,查看索引的shard信息,确认索引的shard在负载高的节点上呈现的数量较多,说明shard分配不均;
GET _cat/shards?v2. 登录Kibana控制台,在开发工具中执行以下命令,查看索引信息。结合集群配置,确认存在节点shard分配不均的现象;
GET _cat/indices?v1、解决方案
重新分配分片,合理规划shard,确保主shard数与副shard数之和是集群数据节点的整数倍;由于Shard大小和数量是影响Elasticsearch集群稳定性和性能的重要因素之一。Elasticsearch集群中任何一个索引都需要有一个合理的shard规划。合理的shard规划能够防止因业务不明确,导致分片庞大消耗Elasticsearch本身性能的问题。以下是shard规划时的几个建议:
1. 尽量遵循索引单分片20g~50g的设计原则;
2. 索引尽量增加时间后缀,按时间滚动,方便管理:
3. 在遵循单分片设计原则的前提下,预测出索引最终大小,并根据集群节点数设计索引分片数量,使分片尽量平均分布在各个节点。
特别注意
主分片不是越多越好,因为主分片越多,Elasticsearch性能开销也会越大。建议单节点shard总数按照单节点内存*30进行评估,如果shard数量太多,极易引起文件句柄耗尽,导致集群故障。
Elasticsearch在检索过程中也会检索 .del 文件,然后过滤标记有 .del 的文档,这会降低检索效率,耗费规格资源,建议在业务低峰期进行强制合并操作,具体请参见[force merge]1。
原因二:集群存在磁盘高水位节点
这里的高水位是指cluster.routing.allocation.disk.watermark.high ,其默认值为90%。这个参数的作用为:当磁盘水位达到90%的节点,es会把该节点上的部分shard迁移到磁盘水位低的节点上去。在这种场景下,很容易出现个别节点被分配了较多的索引,直接造成请求的热点。
2、解决方案
1.临时方案(不推荐):
(1)调整集群水位,临时调到一个比较大的值;
(2)清理旧数据,及时释放出磁盘空间,或者紧急扩容磁盘;
2.长期方案(推荐):
订阅磁盘使用率的告警,保持集群的磁盘水位在一个健康的状态。
原因三:Segment大小不均
1. 在查询body中添加 "profile": true ,检查test索引是否存在某个shard查询时间比其他shard长。
2. 查询中分别指定 preference=_primary 和preference=_replica ,在body中添加 "profile": true ,分别查看主副hard查询消耗的时间。检查较耗时的shard主要体现在主shard上还是副shard上。
3. 登录Kibana控制台,在开发工具中执行以下命令,查看shard,并根据其中segment信息分析问题所在,确认负载不均与segment大小不均有关。
GET_cat/segments/index?v&h=shard,segment,size,size.momery,ipGET _cat/shards?v3、解决方案
参考以下两种方法其中一种解决问题:
1.在业务低峰期进行强制合并操作,具体请参见[force merge]2,将缓存中的delete.doc彻底删除,将小segment合并成大segment。
2.重启主shard所在节点,触发副shard升级为主shard。并且重新生成副shard,副shard复制新的主shard中的数据,保持主副shard的segment一致。
原因四:存在典型的冷热数据需求场景
如果请求中添加了routing或查询频率较高的热点数据,则必然导致数据出现负载不均。
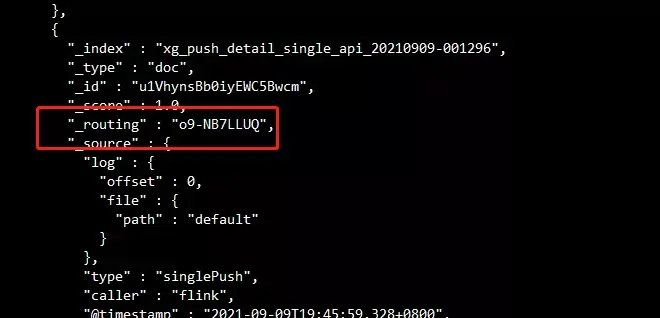
图中可以看到该条doc指定了routing。
4、解决方案
优化分片,慎用routing,避免请求热点。
总结
排查该类问题的关键点,还是在于善用集群的监控指标来快速判断问题的方向,再配合集群日志来定位问题的根因,才能快速地解决问题。
参考资料:
[force merge]1:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices-forcemerge.html
[force merge]2:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices-forcemerge.html
END
