数人之道原创文章,转载请关注本公众号联系我们
之前在《初识 HBase - HBase 基础知识》中提到过,HBase 的数据物理存储格式为多维稀疏排序 Map, 由 key 及 value 组成:
- key 的构成: rowkey+column family+column qualifier+timestamp+type
- value 的构成:字节形式存储
在 key 中的 rowkey 可以唯一标识一行记录,因此 HBase 的查询有以下几种实现方式:
- 通过 get 方式,指定 rowkey 获取唯一一条记录;
- 通过 scan 方式,设置 STARTROW 和 ENDROW 参数进行范围匹配;
- 全表扫描,即直接扫描整张表中所有行记录。
可见,HBase 是通过 rowkey 来进行查询的,rowkey 设计的优劣会直接影响读写性能。一般 rowkey 上都会存放一些比较关键的检索信息,我们需要提前规划好数据具体要如何查询,根据查询方式进行数据存储格式的设计,避免做效率特别低的全表扫描。
那如何才能设计出既符合业务使用逻辑,又能满足系统性能需求的 rowkey 呢?
1预分区
在介绍 rowkey 设计之前,先来了解 HBase 的预分区,因为预分区跟 rowkey 设计密不可分。rowkey 设计完成后,需要通过预分区来落地实现。
1.1HBase 的 split 机制
通常 HBase 会自动处理 Region 的拆分操作,当 Region 的大小到达一定阈值后,会把过大的 Region 一分为二,之后在两个 Region 中都能继续增长数据。这就是 HBase 的 split 机制。
HBase 默认的 Region split 策略是,根据以下公式确定 split 的 maxFileSize:
其中,r为在线 Region 个数,maxFileSize由参数hbase.hregion.max.filesize指定,默认为 10G.
这里假设 flushSize 为 128M,maxFileSize 为默认的 10G,看看 split 的过程:
第一次拆分大小为:min(1*1*128M, 10G)=128M 第二次拆分大小为:min(3*3*128M, 10G)=1152M 第三次拆分大小为:min(5*5*128M, 10G)=3200M 第四次拆分大小为:min(7*7*128M, 10G)=6272M 第五次拆分大小为:min(9*9*128M, 10G)=10G 第六次拆分大小为:min(11*11*128M, 10G)=10G ...
可以看到,只有在第五次之后的拆分大小才为设定的 10G. 因此hbase.hregion.max.filesize 设置得越大,其 split 的上限大小就会越大。
在 HBase 的这个 split 的过程当中,会出现两个问题:
第一,就是我们所说的热点问题(下面会详细介绍),数据会继续往一个 Region 中写,出现写热点问题;
第二,则是拆分合并风暴,当用户的 Region 大小以恒定的速度增长,Region 的拆分会在同一时间发生,因为同时需要压缩 Region 中的存储文件,这个过程会重写拆分后的 Region,这将会引起磁盘 I/O 上升 。
对于拆分合并风暴,通常需要关闭 HBase 的自动管理拆分,然后手动调用 HBase 的 split 和 major_compact,来分散 I/O 负载。但是其中的 split 操作同样是高 I/O 的操作。
1.2
预分区的意义
为了解决这些问题,预分区就是一种很好的方法,通常预分区可以和 rowkey 的设计结合起来使用。
所谓预分区,就是预先创建 HBase 的表分区。在 HBase 中,每一个 Region 维护着 startRowKey 与 endRowKey,如果加入的数据符合某个 Region 维护的 rowkey 范围,则该数据会交给这个 Region 进行维护。因此可以通过预分区,避免出现 split 过程中的热点问题和拆分合并风暴。
在进行预分区之前,需要明确 rowkey 的取值范围和构成逻辑,将数据要存放的分区大致规划好。分区数量建议为 RegionServer 服务器的倍数,这样能保证每个 RegionServer 上的 Region 数量尽可能一样,均衡分布。
例如,rowkey 为:a-abc001、b-abc002、c-abc003,那么预分区就可以设定为:( ,a)、[a,b)、[b,c)、[c, ).
1.3预分区的方法
1.3.1. 手动设定预分区
可在 HBase Shell 中使用以下语句,创建表的同时手动设定预分区:
create 'namespace:table', 'CF', 'partition', SPLITS => []
例如,手动设定 10000 - 50000 的预分区:
create 'datamanroad:Employee', 'info', 'partition1', SPLITS => ['10000','20000','30000','40000','50000']
在 HBase Web 页面上查看新建表的预分区:

图1-3-1:查看手动设定的预分区
可以看到,新建的表 Employee 被预先分成了 6 个分区,每个 RegionServer 各分配到两个分区。
1.3.2. 使用十六进制序列预分区
可在 HBase Shell 中使用以下语句,创建表的同时使用十六进制序列生成预分区:
create 'datamanroad:Employee_alpha', 'info', 'partition2', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
在 HBase Web 页面上查看新建表的预分区:
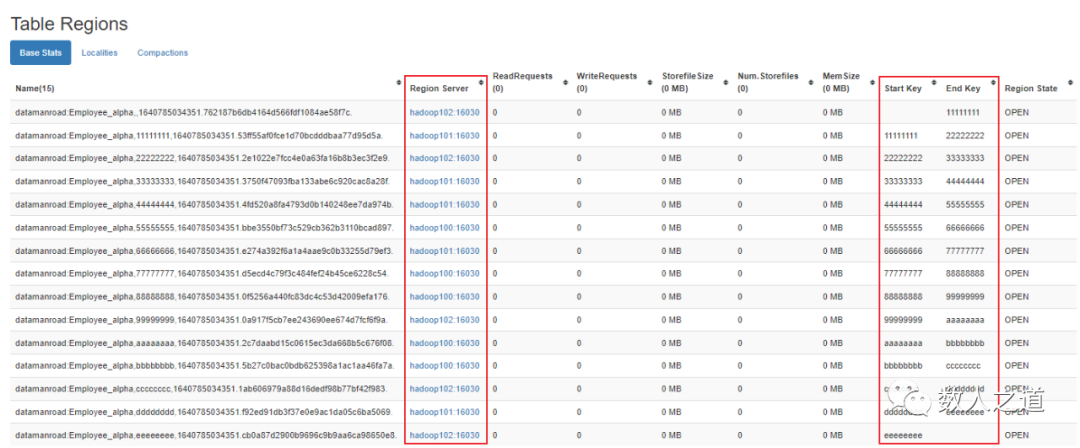
图1-3-2:查看十六进制序列预分区
可以看到,新建的表 Employee_alpha 被预先分成了 15 个分区,每个 RegionServer 各分配到 5 个分区。
1.3.3. 根据文件设置规则预分区
可以按照文件中设置好的序列规则,通过引用文件的方式生成预分区。
先创建规则文件,并添加序列内容:
[hadoop@hadoop100 data]$ vim splits.txt
aaaaa
bbbbb
ccccc
ddddd
eeeee
在 HBase Shell 中执行以下语句,根据文件规则生成预分区:
create 'datamanroad:Employee_beta', 'info', 'partition3', SPLITS_FILE => '/opt/data/splits.txt'
在 HBase Web 页面上查看新建表的预分区:
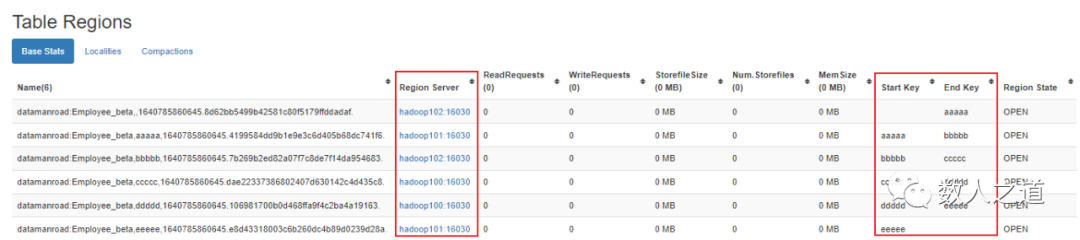
图1-3-3:查看根据文件规则生成的预分区
可以看到,新建的表 Employee_beta 被预先按文件规则分成了 6 个分区,每个 RegionServer 各分配到两个分区。
这里需要注意的是,HBase 会自动对文件中的序列按字典序进行排序,再生成预分区,因此,文件中设置的序列规则对排序没有讲究。
1.3.4. 使用 Java API 预分区
使用 HBase 提供的 Java API 中的 HTableDescriptor 方法,指定 splitKeys 算法,在创建表的同时实现预分区的生成。
注意,这里的 splitKeys 数据结构类型是二维数组。
a. 新建 Maven 项目,在 pom.xml 文件中配置 HBase 的 JAR 包依赖,项目会自动下载所需的依赖包,并自动实现依赖导入:
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.8</version>
</dependency>
</dependencies>
b. 进行预分区前先查看所创建预分区的表是否存在:
//判断表是否存在
public static boolean tableExists(String tableName) throws IOException {
//HBase 配置文件
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop100,hadoop101,hadoop102");
//获取连接对象
Connection connection = ConnectionFactory.createConnection(configuration);
//获取管理员对象
Admin admin = connection.getAdmin();
//执行
boolean tableExists = admin.tableExists(TableName.valueOf(tableName));
//关闭资源
admin.close();
return tableExists;
}
使用此方法,查询需要新建的表 DMR_Employee 是否存在:
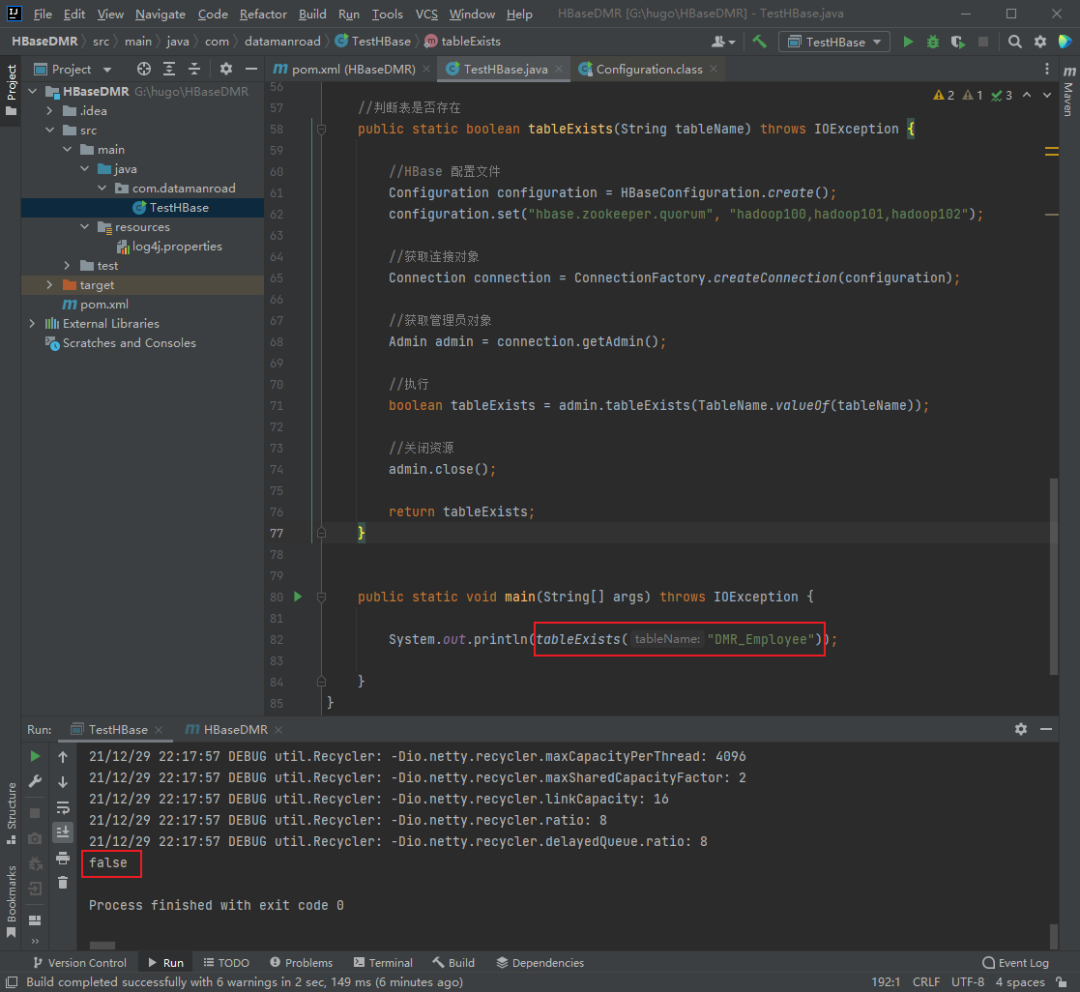
图1-3-4:查看创建预分区的表是否存在
返回的结果是 false,表明查询的表不存在,可以进行预分区创建。
c. 预分区实现方法代码:
//创建表并进行预分区
public static void hBaseSplit() throws IOException {
//HBase 配置文件,配置 Zookeeper 地址,端口默认为 2181
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "hadoop100,hadoop101,hadoop102");
//获取连接对象
Connection connection = ConnectionFactory.createConnection(configuration);
//获取管理员对象
Admin admin = connection.getAdmin();
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = {{1,2,3,4,5}, {'a','b','c','d','e'}};
//通过 HTableDescriptor 创建表
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("DMR_Employee"));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor("info"));
hTableDescriptor.addFamily(new HColumnDescriptor("salary"));
//创建表,并使用自定义算法生成预分区
admin.createTable(hTableDescriptor, splitKeys);
//关闭资源
admin.close();
}
调用此方法,实现预分区的创建:
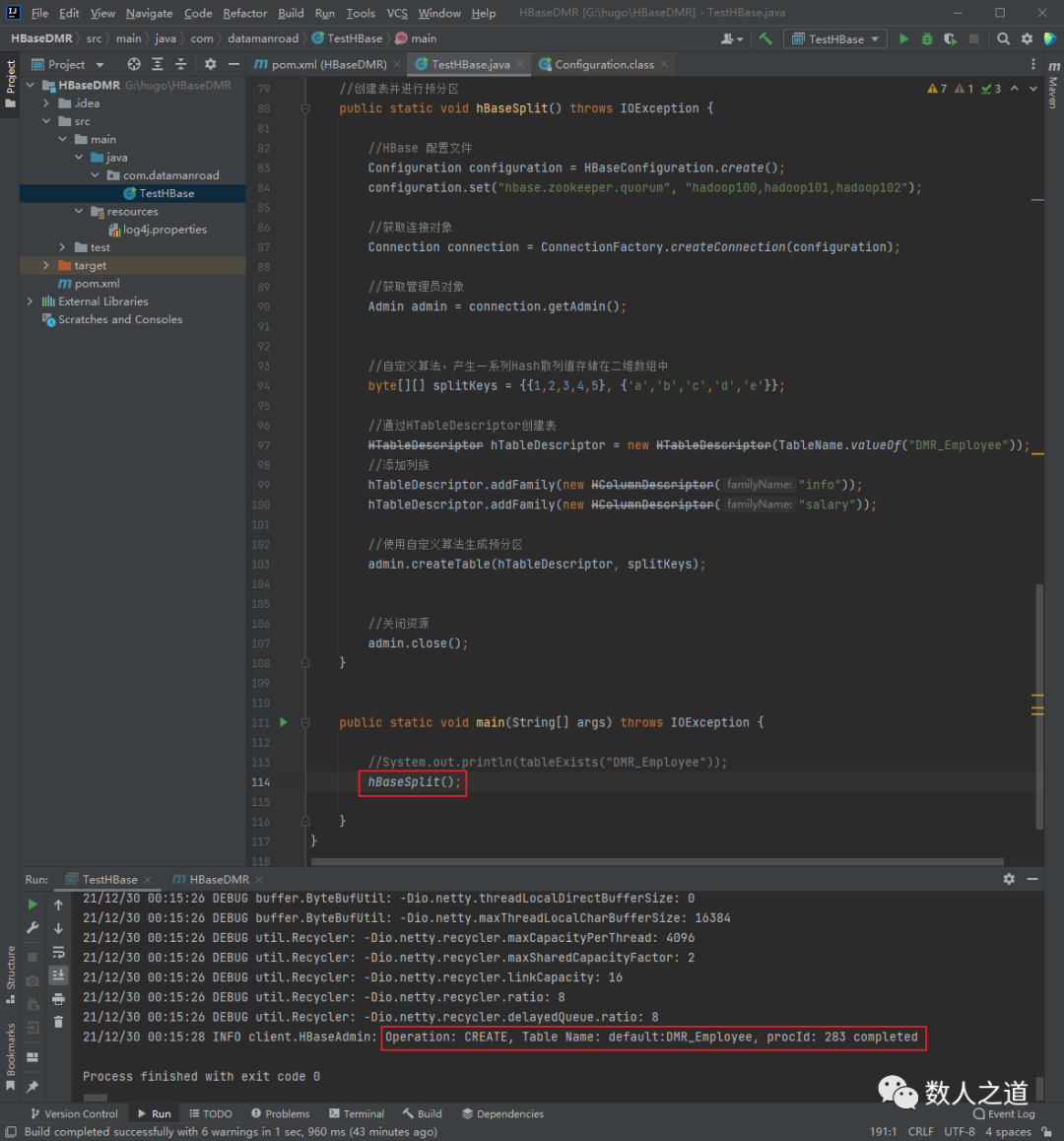
图1-3-5:使用 API 进行预分区操作
在 HBase Web 页面上查看新建表的预分区:

图1-3-6:查看使用 API 创建的预分区
d. 代码运行过程中若出现 log4j 的警告,可在/src/main/resources目录下创建名为log4j.properties的文件,并添加如下内容:
hadoop.root.logger=DEBUG, console
log4j.rootLogger=DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
在运行与调试配置中添加 VM options,配置 log4j 的路径:
-Dlog4j.configuration=file:/G:/hugo/HBaseDMR/src/main/resources/log4j.properties
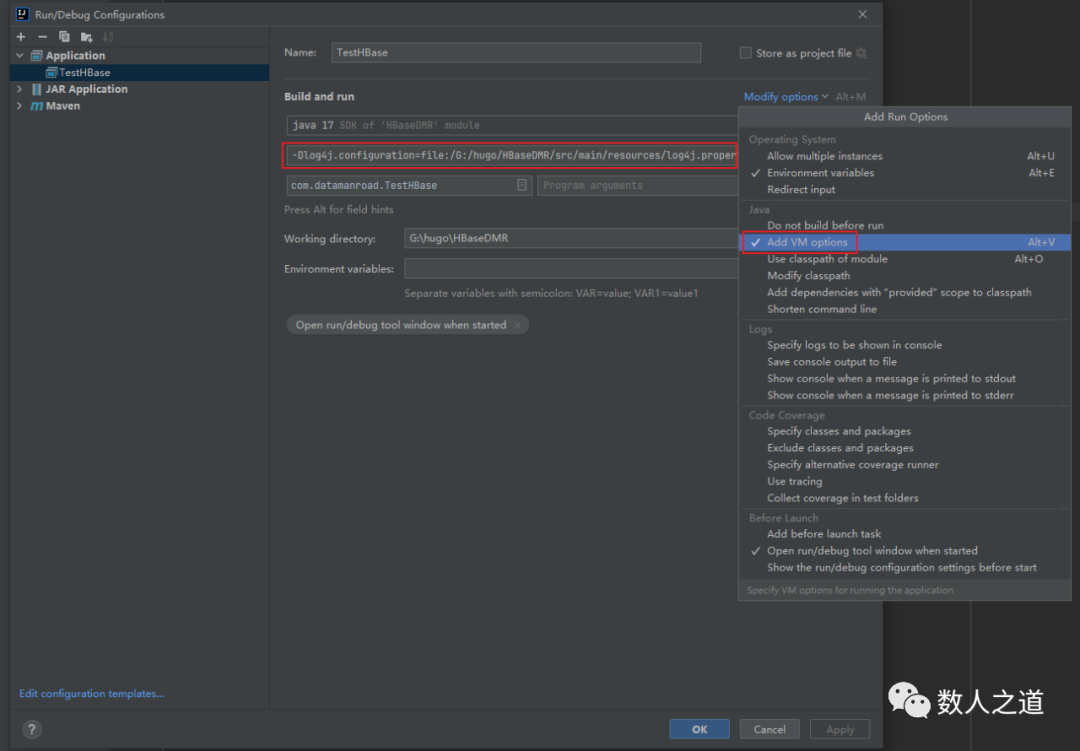
图1-3-7:配置 log4j 属性文件路径
注意替换为自己的项目路径。
2rowkey 设计原则
HBase 中的 rowkey 设计需要遵循以下原则:
2.1rowkey 唯一原则
若在 HBase 中向同一张表插入相同 rowkey 的记录,如没有设置版本数量,则此 rowkey 原先的数据会被覆盖,且 rowkey 是用来唯一标识一行记录的。所以,在 rowkey 的设计上务必要保证其唯一性。
2.2rowkey 排序原则
在《初识 HBase - HBase 基础知识》中我们提到过,rowkey 是按照 ASCII 字典排序(byte order)由低到高存储在表中的。设计 rowkey 时,要充分考虑排序存储这个特性,使用前缀将经常一起读取的行存储到一起。但量不能太大,若太大需要拆分到多个节点上。
注意:字典排序对 int 类型排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21 ... 。因此要保持 int 的自然序,rowkey 必须用 0 作左填充。
2.3rowkey 散列原则
我们设计的 rowkey 应能均匀地散列分布在各个 HBase 的 RegionServer 节点上。下面用常见的时间戳来举例说明这一原则。
若 rowkey 是按系统时间戳的方式递增,而时间戳又位于 rowkey 的第一部分,则会很容易造成热点现象,即所有的新数据会堆积在同一个 RegionServer 上,导致大量的 client 直接访问集群的一个或极少数个节点(访问可能是读、写或者其他操作)。
这种情况会直接导致热点 Region 所在的单个 RegionServer 机器超出自身负载能力,引起性能的下降甚至 Region 不可用。常见的是发生 jvm full gc 或者显示 region too busy 的异常情况。而且由于主机无法服务其他 Region 的请求,因此这种情况还会影响同一个 RegionServer 上的其他 Region。
散列原则的 rowkey 设计就是要使集群被充分、均衡地利用,避免热点现象的发生。散列设计的 rowkey 可以使得不同行在同一个 Region,同时在更多数据的情况下,数据可以被写入集群的多个 Region,而不是一个。
2.4rowkey 长度原则
rowkey 为二进制形式,可以是任意字符串,最大长度为 64kb。而在实际应用中,一般为 10-100bytes,它以 byte[] 形式保存,一般设定为定长格式。
rowkey 的设计建议越短越好,最好不要超过 16 bytes,其原因有三点:
- HBase 的持久化文件 HFile 是按照 Key-Value 存储的,rowkey 是 Key 中的一个域,如果 rowkey 过长(比如 rowkey 是 500 bytes,1000 万行数据,那单是 rowkey 的存储就要占用 500*1000万=50 亿 bytes,将近 5G 的容量),会极大地影响 HFile 的存储效率;
- HBase 中的 MemStore 和 BlockCache,分别对应 Store 级别的写入缓存,和 RegionServer 级别的读取缓存。如果 rowkey 过长,内存的有效利用率就会降低,这样系统就无法缓存更多的数据,检索的效率就会受到影响;
- 目前我们使用的服务器操作系统都是 64 位系统,内存按照 8 字节对齐,因此 rowkey 一般设计成 8 字节的整数倍,这样就能利用操作系统的最佳特性,提高寻址效率。
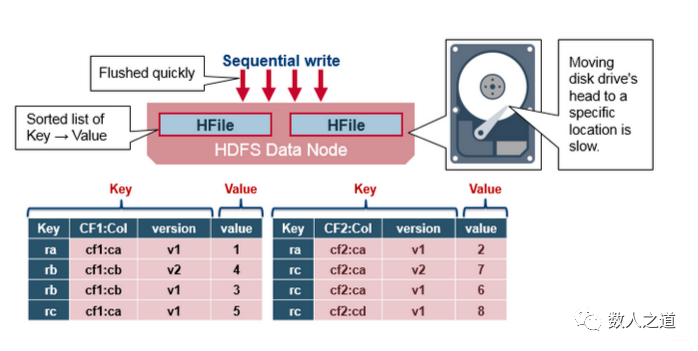
图2-4-1:rowkey 过长会影响 HFile 的存储效率
另外需要注意的是,不仅 rowkey 的长度越短越好,列族名、列名等也尽量不要太长,因为 HBase 属于列式存储数据库,这些名字都会写入到 HBase 的持久化文件 HFile 中。过长的 rowkey、列族、列名都会导致整体的存储量成倍增加,HFile 中的索引最终占据 HBase 分配的大量内存。
3rowkey 设计方法
良好的 rowkey 设计,应当遵循以上四大原则,并且能让数据分散,从而避免热点问题。下面介绍几种常用的 rowkey 设计方法。
3.1Salt 加盐
这里说的 Salt 加盐方法,是给每一个 rowkey 分配一个前缀,前缀使用一些随机字符,使得它和之前的 rowkey 开头不同,以使数据分散在多个不同的 Region 中,达到负载均衡、避免热点的目的。分配的前缀种类数量应该和需要分散到的不同 Region 的数量一致。下面举例说明这种方法的操作和优缺点。
在一个有 4 个 Region 的 HBase 表中(分区为:[ ,a)、[a,b)、[b,c)、[c, )),加盐前的 rowkey 为:abc001、abc002、abc003,此时,数据会默认分在 [a,b) 这个 Region 中。
现在,我们分别为这几个 rowkey 加上 a、b、c 前缀,加盐后的 rowkey 为:a-abc001、b-abc002、c-abc003,此时,数据就会分布在 3 个 Region 中。
理论上,通过 Salt 加盐处理后的数据的写操作吞吐量会是之前的 3 倍。而由于前缀是随机的,读这些数据时需要耗费更多的时间。所以,加盐的优点是增加了写操作的吞吐量,缺点是同时增加了读操作的开销。
3.2Hash 散列或 Mod
使用 Hash 散列来替代随机 Salt 前缀,可以使同一行只用一个前缀,在分散整个集群负载的同时,可以使读操作也能够预测。确定性的 Hash 可以让客户端重构完整的 rowkey,使用 get 操作便能直接准确地获取某一行的数据。下面我们使用加盐中的例子来进一步说明。
将加盐例子中的原始 rowkey 经过 Hash 处理(此处我们采用 md5 散列算法取前 4 位作为前缀),结果如下:9bf0-abc001、7006-abc002、95e6-abc003.
如果以前 4 位的前缀作为不同分区的起止,则这几个 rowkey 的数据会分布在 3 个 Region 中,且读操作能比 Salt 更快速准确。在实际应用场景中,当数据量越来越大,这种设计会使得分区之间更加均衡。
如果 rowkey 是数字类型的,也可以考虑采用 Mod(取模)方法。
3.3Reverse 反转
针对固定长度或者数字格式的 rowkey,可以反转后存储。这样就可以使得 rowkey 中经常改变(也是最没有意义)的部分放在最前面,从而生成有效的随机 rowkey。
以手机号码为例,手机号码的开头都是相对比较固定的,但其后几位都是没有规律的随机数字。因此,我们可以将手机号反转后的字符串作为 rowkey,这样就避免了较为固定的起始字符串(如 138、159、189)导致的热点问题。身份证号码也同样适用。
反转的缺点是牺牲了 rowkey 的有序性。
3.4时间戳反转
时间戳反转实质上是属于反转方法的应用,只是这个反转较为常用,特单独进行讲解。
由于 HBase 中的 rowkey 是按照 ASCII 字典顺序由低到高排序,因此若使用递增的 rowkey,最新产生的数据会被放到旧数据的后面。因此,如果需要快速获取数据的最新记录,可以使用反转的时间戳作为 rowkey 的一部分。
具体实现方式是,用一个大的数(如 99999999)或者 Long 型的最大值(0x7FFFFFFFFFFFFFFF)减去时间戳,结果放到 rowkey 的后面作为其一部分。这样就可以调整数据的时间排序,将最新的数据放在前面,通过 scan 操作获取第一条记录即为最新的值。但这个方法严格上来说,并没有完全遵循散列原则。
举例来说,需要保存用户的操作记录,就可以使用时间戳反转的方法设计 rowkey:
[userID反转][Long.Max_Value - timestamp]
查询用户的所有操作记录:使用 scan 操作指定范围,STARTROW 为[userID反转][000000000000],ENDROW 为[userID反转][Long.Max_Value - timestamp].
查询用户某段时间的操作记录:使用 scan 操作指定范围,STARTROW 为[userID反转][Long.Max_Value - 起始时间],ENDROW 为[userID反转][Long.Max_Value - 结束时间].
rowkey 的设计除了掌握原理和方法外,还需要多加实践,有些小技巧是需要在实践中摸索和积累的。例如,在 rowkey 中使用|,~等 ASCII码较大的字符来避免排序混乱或人工干预排序等。
在 rowkey 设计完成之后,即可通过使用预分区的方法,来指定按设计好的 rowkey 进行预分区了。
THE END
