split
hbase是通过regionServer管理table的,一个table对应一个或多个region,hmaster将这些region根据集群负载分配给regionServer进行管理。若一个table没有进行预分区,那么只有一个region,初始化表时数据的读写都命中同一个regionServer,会造成热点问题,且region进行split时集群是不可用的,频繁的split也会造成大量的集群I/O,性能很低。
1、pre-splitting
在创建table时指定pre-splitting,预先生成多个region,结合合适的rowkey,这样可以很大程度上避免读写热点,每个region内部再按照一定的split-policy进行自动切分。
hbase提供了两种pre-split算法:HexStringSplit和UniformSplit,前者适用于十六进制字符的rowkey,后者适用于随机字节数组的rowkey。
1.1、HexStringSplit
shell建表语句:
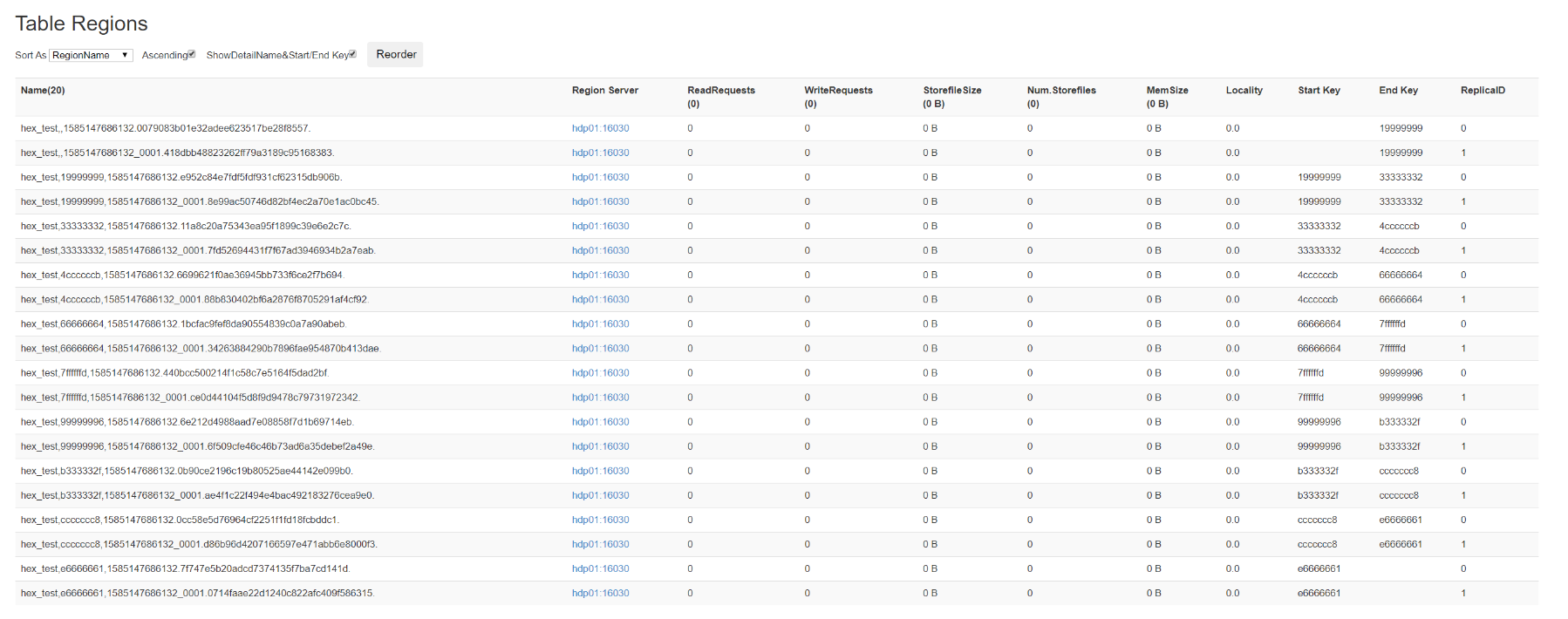
//创建一个名为hex_test的表,有两个列簇info和desc,可存3个版本的数据,副本为2,预先指定10个region,且split算法为HexStringSplit
create 'hex_test',{NAME=>'info',VERSIONS=>3},{NAME=>'desc',VERSIONS=>3},{NUMREGIONS=>10,SPLITALGO=>'HexStringSplit',REGION_REPLICATION=>2}
可以在web ui看到这张表的信息:
1.2、UniformSplit
shell建表:
create 'uniform_test',{NAME=>'info',VERSIONS=>3},{NAME=>'desc',VERSIONS=>3},{NUMREGIONS=>10,SPLITALGO=>'UniformSplit',REGION_REPLICATION=>2}
1.3、自定义切分点
//1、直接指定切分点
create 'c_test1','info',{SPLITS=>['10','20','30']}
//2、指定切分文件
create 'c_test2','info',SPLITS_FILE=> '/home/syui/data/hbase/split_file/t1.txt'
2、自动splitting
regionServer根据split policy对region进行切分。不同的切分策略可以应用在不同的业务场景,所以可以根据需求设置table级别的split policy;也可以在hbase-site.xml中使用hbase.regionserver.region.split.policy设置全局的split policy;还可以自己实现split policy。
//创建一个policy_table表,使用IncreasingToUpperBoundRegionSplitPolicy切分策略
create 'policy_test','info',{CONFIGURATION=>{'hbase.regionserver.region.split.policy'=>'IncreasingToUpperBoundRegionSplitPolicy'}}
hbase提供了6种切分策略。
2.1、ConstantSizeRegionSplitPolicy
当region的最大一个store达到指定的阈值时触发split,这个阈值可以使用hbase.hregion.max.filesize设置(默认10G)。0.94版本前的默认切分策略。
2.2、IncreasingToUpperBoundRegionSplitPolicy
也是当region的最大一个store达到一个阈值时触发split,不过这个阈值不是固定的,而是根据regionServer管理的同属一张表的region个数有关:
a)、region个数为0或者大于100:maxFilesize的选取跟ConstantSizeRegionSplitPolicy一样;
b)、region个数在0~100之间:有一个initialSize,这个值由hbase.incresing.policy.initial.size配置;若没有配置这个值,则initialSize = 2 * MEMSTORE_FLUSHSIZE(table元数据);若table没有元数据或initialSize小于0,则initialSize = 2 * hbase.hregion.memstore.flush.size(默认128M)。拿到initialSize后,maxFilesize = min (initialSize * region个数的3次方, 10G)。
0.94 ~ 2.0版本默认的切分策略,这种策略下,表的region越少,split越频繁,当region数超过4之后的maxFilesize都是10G。
2.3、SteppingSplitPolicy
这是IncresingToUpperBoundRegionSplitPolicy的子类,重写了getSizeToCheck方法,当region个数为1时,maxFilesize = flushSize * 2,其他情况跟父类一样。
2.0版本后的默认切分策略,修改了1个region时的切分阈值,之前是128 * 1^3 = 128M,现在是128 * 2 * 1^3 = 256M。
2.4、KeyPrefixRegionSplitPolicy
这是IncresingToUpperBoundRegionSplitPolicy的子类,切分条件跟父类一样,修改了splitKey的选取,会根据rowkey的前缀对数据分组,将rowkey前缀相同的数据在split时分到相同的region中,前缀位数可以使用默认的,也可以使用table元数据KeyPrefixRegionSplitPolicy.prefix_length设置。
2.5、DelimitedKeyPrefixRegionSplitPolicy
跟keyPrefixRegionSplitPolicy一样继承自IncresingToUpperBoundRegionSplitPolicy,切分条件不变,也是修改了splitKey的选取,会根据指定的分隔符截取rowkey前部分字符,将该部分字符相同的数据在split时分到同一个region,分隔符可以使用table元数据DelimitedKeyPrefixRegionSplitPolicy.delimiter设置。
2.6、DisableSplitPolicy
禁用region自动split。
3、强制split
split 'split_test','0326' //切分split_test表,以0326为切分点
