
近日,由天翼云弹性网络产品线撰写的《Small Scale Data-free Knowledge Distillation》长文被IEEE Conference on Computer Vision and Pattern Recognition收录。

IEEE CVPR是人工智能与模式识别技术领域的顶/级国际学术会议,也是中国计算机学会CCF推荐的A类国际会议之一。该会议始于1983年,是业界公认的全球计算机视觉三大顶/级会议之一。此次论文被IEEE CVPR成功收录,不仅展现了天翼云在AI领域的创新能力,也意味着中国企业在国际学术舞台上的影响力日益增强。
《Small Scale Data-free Knowledge Distillation》这篇长文提到,知识蒸馏技术(Knowledge Distillation)可以利用预训练的众多网络信息,在相同的训练数据上训练一个更小的新建特定网络。传统的知识蒸馏方法假设原始训练数据总是可以获得的,但在实际应用中,由于网络用户关注数据隐私和安全问题,通常无法获取网络的训练数据集。为了放宽对获取训练数据的限制,零数据条件下的知识蒸馏技术应运而生。
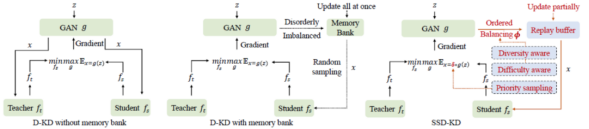
本论文提出了基于小规模逆向生成数据的零数据知识蒸馏技术(Small Scale Data-free Knowledge Distillation,下文简写为SSD-KD),引入了两个相互依赖的模块,显著加快了逆向生成数据的质量和蒸馏范式的整体训练效率。SSD-KD的第一个模块依赖于一个新颖的调制函数,定义了样本多样性分布感知项和样本难度分布感知项,以显式方式共同平衡了逆向生成数据过程中的数据样本分布。
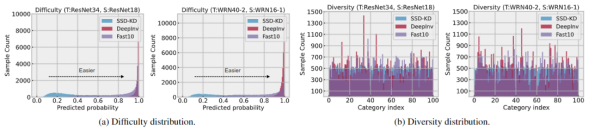
第二个模块定义了借鉴强化学习优化策略的优先级采样函数。该函数选择适当的逆向生成样本来更新动态重放缓冲区中的一部分现有样本,进一步提高了逆向生成样本在知识蒸馏中的采样效率。得益于上述两个模块,本论文所提出的方法可极大地满足客户对于高性能、高效率的需求。一方面,SSD-KD可以在极小规模的合成样本(比原始训练数据规模少10倍)条件下进行网络蒸馏训练,使得整体训练效率比众多主流零数据知识蒸馏方法快一到两个数量级,同时保持有竞争力的模型性能。另一方面,当放宽逆向生成样本的数据规模到一个相对较大的数字(尽管仍然小于现有零数据知识蒸馏方法的规模)时,论文中提出的方法在更小的新建特定网络的准确性上取得了大幅改进,并保持了整体训练效率。该方法已在不同人工智能应用上进行实验,验证了方法的普适性。同时,天翼云将把论文中提出的人工智能模型训练方法,应用于弹性网络智能运维的深度学习模型训练中,让深度学习模型适配更多的弹性网络环境,让弹性网络更高效,更智能。

人工智能的蓬勃发展激荡新一轮产业变革,天翼云弹性网络产品线今后将持续发力云网络领域的架构创新及高新技术预备研发,不断攻坚提升云网络的关键性能指标;针对广泛的人工智能和机器学习业务应用,基于智能算力架构平台,结合云网融合、智能运维等技术,赋予网络在人工智能及大模型领域内模型的高可用、低时延和强鲁棒等特性。
面向未来,天翼云将通过不断地科技创新与服务优化,推动云计算、人工智能等新兴技术融合发展,为各行各业的数字化转型提供更加智能、高效、安全的云服务体验,为经济社会的高质量发展注入源源不断的新动能。
