1.问题
今天又在mysql中遇到了,吐血。

2.解决方案
SQL最后加上
COLLATE utf8mb4_unicode_ci

SELECT t2.cust_id as cust_id_ex,t1.* from
(
SELECT * from credit_nigeria.apply WHERE updateTime>"2019-11-10"
) t1
RIGHT JOIN
(
SELECT cust_id from bank_nigeria.ng_trans_record WHERE update_Time>"2019-11-18 04" and update_Time<"2019-11-18 05" and pay_type="xx"
) t2
on
t1.custid=t2.cust_id COLLATE utf8mb4_unicode_ci order by t2.cust_id, updateTime desc ;
在哪里加?
我也不太知道。。。都是试。表后面,字段后面,变量后面
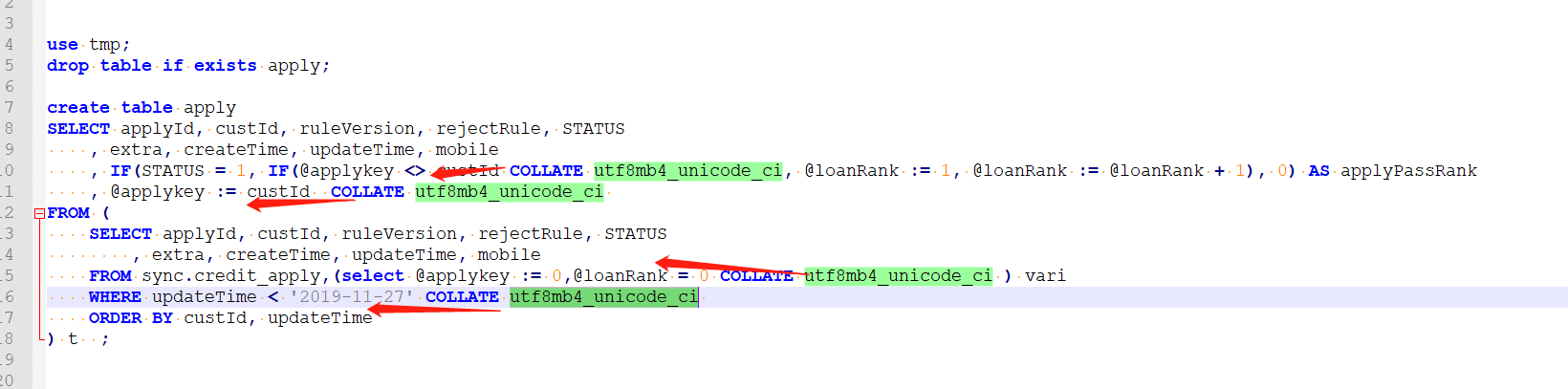
案例:
案例一
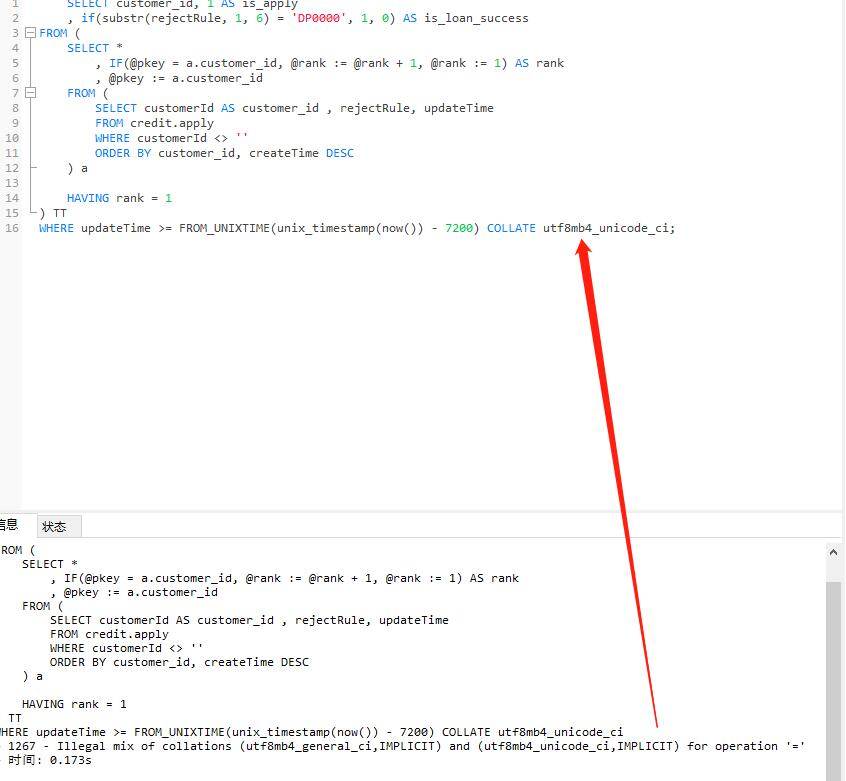
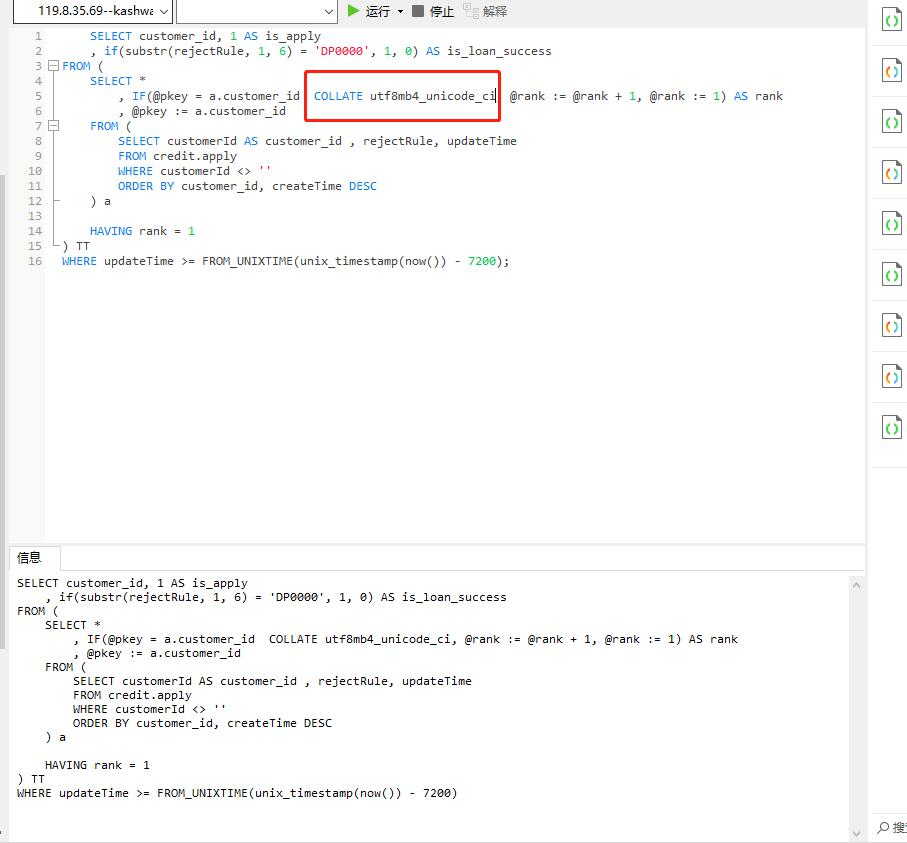
案例二:
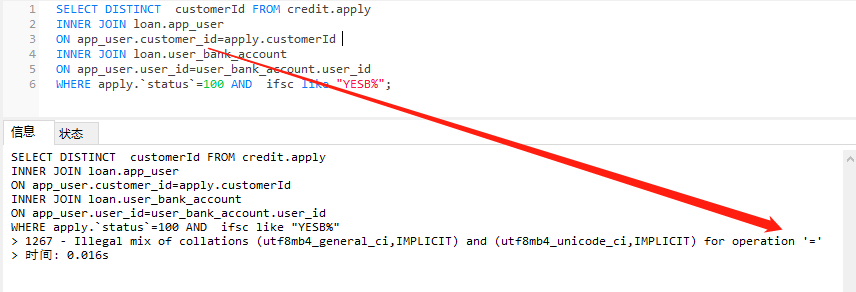
3.原理
utf8mb4对应的排序字符集有utf8mb4_unicode_ci、utf8mb4_general_ci.
utf8mb4_unicode_ci和utf8mb4_general_ci的对比:
- 准确性:
- utf8mb4_unicode_ci是基于标准的Unicode来排序和比较,能够在各种语言之间精确排序
- utf8mb4_general_ci没有实现Unicode排序规则,在遇到某些特殊语言或者字符集,排序结果可能不一致。
但是,在绝大多数情况下,这些特殊字符的顺序并不需要那么精确。
- 性能
- utf8mb4_general_ci在比较和排序的时候更快
- utf8mb4_unicode_ci在特殊情况下,Unicode排序规则为了能够处理特殊字符的情况,实现了略微复杂的排序算法。
但是在绝大多数情况下发,不会发生此类复杂比较。相比选择哪一种collation,使用者更应该关心字符集与排序规则在db里需要统一。
