Elasticsearch上的索引如果有多个分片,那么在聚合排序后取TopN时,返回的结果可能是不准的,今天我们就通过实战来研究分析此问题,并验证解决方法;
环境信息
以下是本次实战的环境信息,请确保您的Elasticsearch可以正常运行:
- 操作系统:Ubuntu 18.04.2 LTS
- JDK:1.8.0_191
- Elasticsearch:6.7.1
- Kibana:6.7.1
系列文章列表
- 《Elasticsearch聚合学习之一:基本操作》;
- 《Elasticsearch聚合学习之二:区间聚合》;
- 《Elasticsearch聚合学习之三:范围限定》;
- 《Elasticsearch聚合学习之四:结果排序》;
- 《Elasticsearch聚合学习之五:排序结果不准的问题分析》;
复现问题第一步:创建索引
首先是将问题复现,这里我做了个简单的索引,只有两个字段,将索引分为两个分片,然后准备了一些数据写入这两个分片;
在Kibana的Dev Tools执行以下命令,即可创建名为taskcase的索引,该索引有两个分片,只有两个字段:name和value:
PUT /testcase
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 2
},
"mappings" : {
"t1" : {
"properties" : {
"name" : {
"type" : "keyword"
},
"value" : {
"type" : "long"
}
}
}
}
}
接下来是导入数据了。
复现问题第二步:导入数据
为了测试的准确性,按照以下要求来制造测试数据:
- 按照name字段聚合,name的值不宜太多,否则会有过多的桶不好分析结果;
- 能精确的指定哪些数据到分片1,哪些到分片2;
对于这份测试数据,这里先给出聚合结果(在生成数据的时候计算出来的),有了这些结果,我们就能和es聚合结果做对比,发现问题所在:
分片一,按name聚合后,name相同的文档value字段之和:
14 : 22491 //14是name,22491是所有name等于14的文档的value字段之和
8 : 21632
4 : 21502
15 : 21234
26 : 20731
10 : 20306
17 : 19942
9 : 19418
25 : 19191
16 : 18797
6 : 18306
3 : 18166
22 : 17669
24 : 16971
27 : 16911
18 : 16758
23 : 16527
13 : 15705
7 : 15251
11 : 15019
12 : 14387
2 : 14329
30 : 14023
5 : 13421
29 : 13309
1 : 12574
28 : 12189
19 : 11673
21 : 11460
20 : 10576
分片二,按name聚合后,name相同的文档value字段之和:
19 : 168589
21 : 164705
16 : 162088
9 : 161579
8 : 160459
28 : 159775
15 : 158124
26 : 156609
24 : 156208
11 : 153976
4 : 153479
23 : 152833
12 : 152052
20 : 150718
29 : 150320
17 : 149352
10 : 148473
2 : 147812
5 : 147791
3 : 146158
6 : 145604
7 : 145439
18 : 144984
13 : 144784
14 : 144004
27 : 143564
30 : 140984
22 : 140309
25 : 133879
1 : 133233
所有数据,按name聚合后,name相同的文档value字段之和:
8 : 182091
9 : 180997
16 : 180885
19 : 180262
15 : 179358
26 : 177340
21 : 176165
4 : 174981
24 : 173179
28 : 171964
23 : 169360
17 : 169294
11 : 168995
10 : 168779
14 : 166495
12 : 166439
3 : 164324
6 : 163910
29 : 163629
2 : 162141
18 : 161742
20 : 161294
5 : 161212
7 : 160690
13 : 160489
27 : 160475
22 : 157978
30 : 155007
25 : 153070
1 : 145807
这份数据集保存在bulk.json文件中,您可以在此下载:
https://raw.githubusercontent.com/zq2599/blog_demos/master/files/bulk.json
下载后,用curl命令导入这些数据:
curl -H 'Content-Type: application/x-ndjson' -s -XPOST http://192.168.50.75:9200/testcase/t1/_bulk --data-binary @bulk.json
在bulk.json中,由routing的值来决定数据会存在哪个分片中,已经验证过routing=a时会写入第一个分片,routing=b时写入第二个分片,因此整个bulk.json中的routing的值只有a和b两种;
上述数据和统计结果都是用java生成的,对应的源码地址在此:
https://raw.githubusercontent.com/zq2599/blog_demos/master/files/GenerateESAggSortData.java
现在数据已经准备好了,可以复现问题了;
复现问题
导入数据成功后,执行以下命令,按照name做聚合,将name相同的文档的value字段的值相加:
GET /testcase/t1/_search
{
"size":0,
"aggs":{
"names":{
"terms": {
"field": "name",
"size" :5,
"order": {
"values": "desc"
}
},
"aggs": {
"values": {
"sum": {
"field": "value"
}
}
}
}
}
}
得到的结果如下:
"buckets" : [
{
"key" : "8",
"doc_count" : 356,
"values" : {
"value" : 182091.0
}
},
{
"key" : "9",
"doc_count" : 356,
"values" : {
"value" : 180997.0
}
},
{
"key" : "16",
"doc_count" : 351,
"values" : {
"value" : 180885.0
}
},
{
"key" : "15",
"doc_count" : 347,
"values" : {
"value" : 179358.0
}
},
{
"key" : "26",
"doc_count" : 353,
"values" : {
"value" : 177340.0
}
}
]
问题已经出现了,返回的数据中,第四名的name是15,但实际上19才是第四名,对比列表如下:
| 排名 | 真实数据 | Elasticsearch返回 |
|---|---|---|
| 1 | 8 : 182091 | 8:182091 |
| 2 | 9 : 180997 | 9:180997 |
| 3 | 16 : 180885 | 16:180885 |
| 4 | 19 : 180262 | 15:179358 |
| 5 | 15 : 179358 | 26:177340 |
分析问题
- 在聚合排序的操作中,实际上是每个分片自身先做排序,然后将每个分片的前17名放在一起再次聚合,再排序,将排序后的前5条记录作为结果返回;
- 为什么用每个分片的前17名?这是用官方给出的算式得来的,地址是:https://www.elastic.co/guide/en/elasticsearch/reference/6.1/search-aggregations-bucket-terms-aggregation.html ,如下图:

如果请求只发往一个分片,就返回前5条,如果发往多个分片,每个分片返回的条数是:5*1.5+10=17
用一幅图来描述,如下图,汇总数据中的紫色,是由分片一和分片二中的紫色合成的:
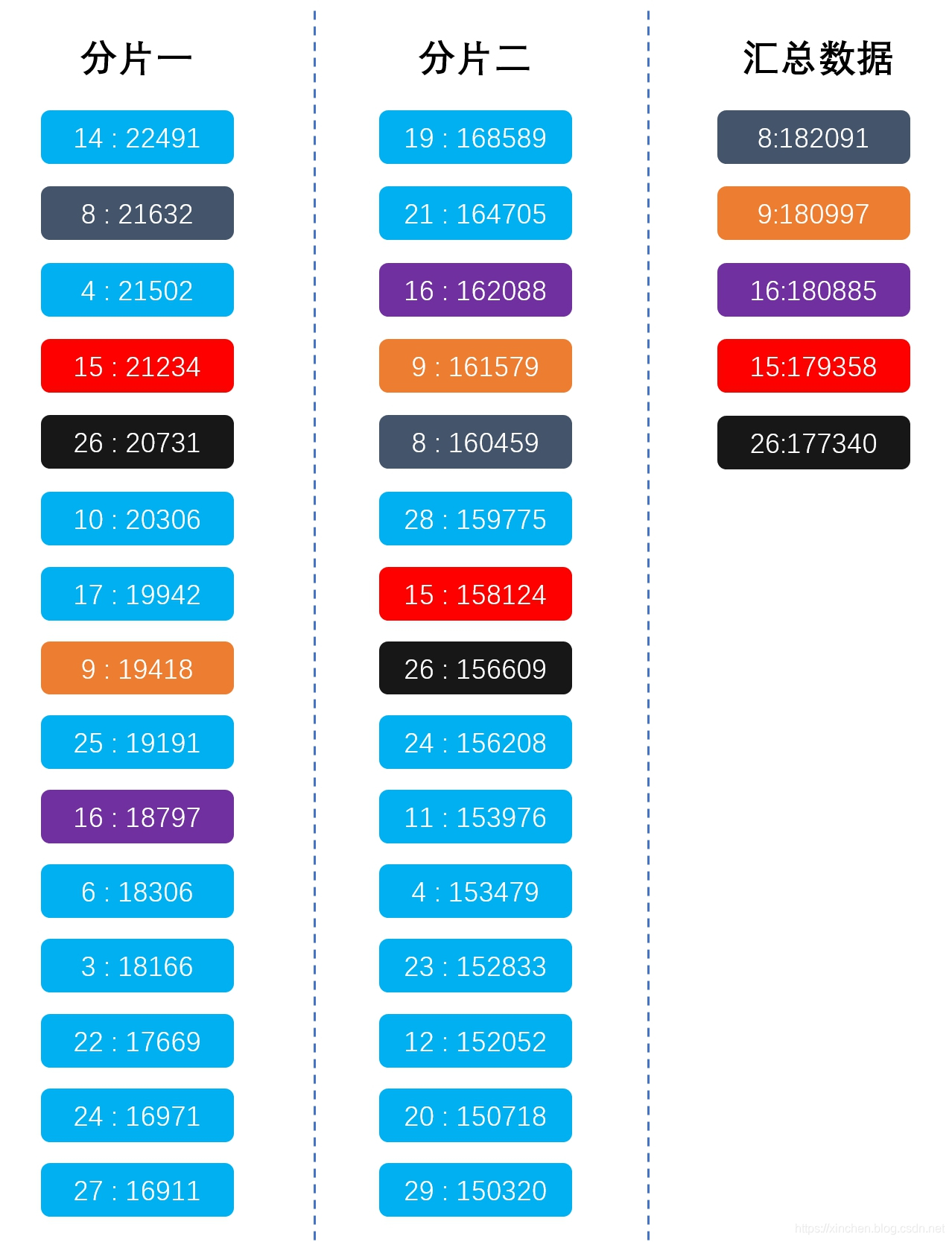
如上图所示,分片一的前17条记录中,没有name等于19的记录(因为该记录在分片一的排名是28),所以两个分片的数据聚合后,name等于19的记录只有分片二的数据中有,即19:168589,这个值在汇总数据中是排不上前5的,于是ES返回的Top5与真实数据的Top5就不一样了,这就是Elasticsearch聚合后排序不准的原因。
接下来看看如何解决此问题
解决办法之一
知道问题的原因解决起来就容易了:如果每个分片返回的不是前17名,而是前28名,那么两个分片中都含有name等于19的记录,这个指定分片返回数量的参数是shard_size,加上shard_size参数的整个请求如下:
GET /testcase/t1/_search
{
"size":0,
"aggs":{
"names":{
"terms": {
"field": "name",
"size" :5,
"shard_size": 28,
"order": {
"values": "desc"
}
},
"aggs": {
"values": {
"sum": {
"field": "value"
}
}
}
}
}
}
得到结果如下,与真实排名一致:
"buckets" : [
{
"key" : "8",
"doc_count" : 356,
"values" : {
"value" : 182091.0
}
},
{
"key" : "9",
"doc_count" : 356,
"values" : {
"value" : 180997.0
}
},
{
"key" : "16",
"doc_count" : 351,
"values" : {
"value" : 180885.0
}
},
{
"key" : "19",
"doc_count" : 348,
"values" : {
"value" : 180262.0
}
},
{
"key" : "15",
"doc_count" : 347,
"values" : {
"value" : 179358.0
}
}
]
由此可以看出:shard_size越大,得到的结果准确率越高,如果shard_size不低于桶的数量,那么就是准确值了。
但实际生产环境中需要结合实际情况来设置shard_size,因为该值越大汇总的数据量就越大,对网络、内存等资源的消耗都会增加,会影响整体性能;
解决办法之二
第二种解决方式就是所有的数据都在一个分片上,具体的方法是创建索引时分片数设置为1,或者在增加数据时指定routing,并且查询的时候也使用该routing,这些方法您可以自行验证,创建一个分片的索引的脚本如下:
PUT /testcase
{
"settings": {
"number_of_replicas": 1,
"number_of_shards": 1
},
"mappings" : {
"t1" : {
"properties" : {
"name" : {
"type" : "keyword"
},
"value" : {
"type" : "long"
}
}
}
}
}
至此,关于聚合排序不准的实战和分析就全部完成了,在您使用es的聚合后TopN时如果遇到类似问题,希望此文能够给您提供一些参考;
欢迎关注我的公众号:程序员欣宸

